Consultas com Spark SQL
- JP

- 15 de jan. de 2021
- 3 min de leitura
Spark SQL faz parte do core do Apache Spark e permite consultas estruturadas dentro do contexto Spark utilizando SQL. Com Spark SQL é possível conectar em diversos datasources como Avro, ORC, JSON, Parquet e dentre outros.
Neste tutorial vamos utilizar como datasource um arquivo JSON para mostrar os poderosos recursos do Spark SQL.
Maven
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>3.1.0</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.12</artifactId>
<version>3.1.0</version>
</dependency>
Configurar o contexto Spark
No passo seguinte, criaremos o SparkSession. Pense que neste ponto você pode reutiliza-lo em sua aplicação, então pense em um classe Singleton para alocar este objeto na inicialização. No exemplo a seguir não farei isso para que fique mais prático e simples.
public class SparkSql {
public static void main(String[] args) {
SparkConf sparkConf = new SparkConf();
sparkConf.setAppName("spark-sql-app");
sparkConf.setMaster("local[1]");
SparkSession session = SparkSession
.builder()
.config(sparkConf)
.getOrCreate();
}
}O objeto SparkConf é responsável pela configuração da Session, perceba que é um objeto simples com os atributos appName e master. O atributo master é uma configuração especifica caso a aplicação execute em um cluster, como nesse exemplo é local, então o valor [1] é o suficiente para a execução e por fim o appName é o nome da aplicação.
Listagem 1 - Select simples
Conteúdo do arquivo produto.json
{"id":1, "nome":"arroz", "preco":12.0, "qtde": 50}
{"id":2, "nome":"feijao", "preco":7.50, "qtde": 30}
{"id":3, "nome":"coca-cola", "preco":5.50, "qtde": 150}
{"id":4, "nome":"suco", "preco":3.80, "qtde": 250}
{"id":5, "nome":"milho", "preco":1.50, "qtde": 33}
{"id":6, "nome":"yogurte", "preco":6.0, "qtde": 15}
{"id":7, "nome":"leite", "preco":3.70, "qtde": 250}
{"id":8, "nome":"oleo", "preco":5.60, "qtde": 100}public static void main(String[] args) {
SparkConf sparkConf = new SparkConf();
sparkConf.setAppName("spark-sql-app");
sparkConf.setMaster("local[1]");
SparkSession session = SparkSession
.builder()
.config(sparkConf)
.getOrCreate();
Dataset<Row> dataFrame = session.read().json("produto.json");
dataFrame.createOrReplaceTempView("produto");
Dataset<Row> sqlFrame = session.sql("select * from produto");
sqlFrame.show();
}Neste exemplo acima é uma forma simples de listar todo o conteúdo do arquivo através de um DataFrame.
Um DataFrame é basicamente uma coleção de dados distribuídos que se assemelha bastante com uma tabela relacional.
Neste trecho é criado uma view temporária com base no Dataframe que foi carregado pela sessão.
dataFrame.createOrReplaceTempView("produto");No próximo trecho é executado uma consulta SQL simples com base na view criada anteriormente.
Dataset<Row> sqlFrame = session.sql("select * from produto");Por fim é executado o método .show() que é uma ação do Spark. Este método lista todos os registros da coleção. É possível passar como argumento neste método a quantidade de registros para listagem, o valor padrão é de 20 registros.
sqlFrame.show();Resultado da execução

Listagem 2 - Cláusula Where
public static void main(String[] args) {
SparkConf sparkConf = new SparkConf();
sparkConf.setAppName("spark-sql-app");
sparkConf.setMaster("local[1]");
SparkSession session = SparkSession
.builder()
.config(sparkConf)
.getOrCreate();
Dataset<Row> dataFrame = session.read().json("produto.json");
dataFrame.createOrReplaceTempView("produto");
Dataset<Row> sqlFrame = session.sql("select nome, preco " +
"from produto " +
"where preco >= 5.0");
sqlFrame.show();
}Resultado da execução

Listagem 3 - Between
public static void main(String[] args) {
SparkConf sparkConf = new SparkConf();
sparkConf.setAppName("spark-sql-app");
sparkConf.setMaster("local[1]");
SparkSession session = SparkSession
.builder()
.config(sparkConf)
.getOrCreate();
Dataset<Row> dataFrame = session.read().json("produto.json");
dataFrame.createOrReplaceTempView("produto");
Dataset<Row> sqlFrame = session.sql("select " +
"nome, preco, qtde " +
"from produto " +
"where qtde between 10 and 50 ");
sqlFrame.show();
}Resultado da execução

Listagem 4 - Sum
public static void main(String[] args) {
SparkConf sparkConf = new SparkConf();
sparkConf.setAppName("spark-sql-app");
sparkConf.setMaster("local[1]");
SparkSession session = SparkSession
.builder()
.config(sparkConf)
.getOrCreate();
Dataset<Row> dataFrame = session.read().json("produto.json");
dataFrame.createOrReplaceTempView("produto");
Dataset<Row> sqlFrame = session.sql("select " +
"sum(preco * qtde) as total " +
"from produto " +
"where qtde > 100 ");
sqlFrame.show();
}Resultado da execução
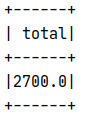
Conteúdo do arquivo produto.json alterado
{"id":1,"nome":"arroz","preco":12.0,"qtde":50,"tipo":"sólido"}
{"id":2,"nome":"feijao","preco":7.50,"qtde":30,"tipo":"sólido"}
{"id":3,"nome":"coca","preco":5.50,"qtde":150,"tipo":"líquido"}
{"id":4,"nome":"suco","preco":3.80,"qtde":250,"tipo":"líquido"}
{"id":5,"nome":"milho","preco":1.50,"qtde":33,"tipo":"sólido"}
{"id":6,"nome":"yogurte","preco":6.0,"qtde":15,"tipo":"líquido"}
{"id":7,"nome":"leite","preco":3.70,"qtde":250,"tipo":"líquido"}
{"id":8,"nome":"oleo","preco":5.60,"qtde":100,"tipo":"líquido"}
Listagem 5 - Count + group by + having
public static void main(String[] args) {
SparkConf sparkConf = new SparkConf();
sparkConf.setAppName("spark-sql-app");
sparkConf.setMaster("local[1]");
SparkSession session = SparkSession
.builder()
.config(sparkConf)
.getOrCreate();
Dataset<Row> dataFrame = session.read().json("produto.json");
dataFrame.createOrReplaceTempView("produto");
Dataset<Row> sqlFrame = session.sql("select " +
"tipo, count(tipo) as qtde" +
"from produto " +
"group by tipo " +
"having (tipo = 'sólido') ");
sqlFrame.show();
}Resultado da execução

Tentei mostrar alguns exemplos simples de como utilizar o Spark SQL e o que ele é capaz, espero ter ajudado no entendimento e até mais.
Documentação: https://spark.apache.org/sql/
Github: https://github.com/apache/spark



Comentários