#6 Orquestração de Pipelines: Airflow e Spark na prática
- JP

- 2 de out. de 2025
- 3 min de leitura
Série: Trilha prática para se tornar Engenheiro de Dados – Capítulo 6
Pré-requisitos importantes antes de usar o Apache Spark
Antes de mergulhar no Spark, garanta que você tem:
Ter acompanhado os Capítulos 1 a 5 e o ambiente preparado conforme mostrado neles:
Introdução

Até aqui, você já aprendeu:
a importância do Engenheiro de Dados no ecossistema,
como Python e SQL se complementam,
os conceitos de Data Lake, Data Warehouse e Lakehouse,
como criar DAGs simples no Airflow,
e como processar dados em escala com o Spark.
Agora vamos conectar os pontos. Neste capítulo, você vai aprender a orquestrar um pipeline Spark dentro do Airflow, unindo a escalabilidade do Spark com o controle e monitoramento do Airflow.
Por que orquestrar Spark com Airflow?
Imagine que você já tem um ETL em Spark funcionando (como vimos no Capítulo 5). Mas e se você precisar:
rodar esse pipeline todos os dias,
monitorar erros,
registrar logs de execução,
e integrar com outros processos (ex.: enviar e-mail, mover arquivos, atualizar dashboards)?
Rodar tudo manualmente seria inviável. É aqui que entra a orquestração.O Airflow permite agendar, monitorar e coordenar jobs Spark (ou qualquer outro tipo de tarefa).
Criando a DAG que orquestra o Spark
Agora vamos criar uma DAG que orquestra o ETL em Spark desenvolvido no Capítulo 5.
Passo 1 – Crie o arquivo da DAG
Salve este código na pasta de DAGs (dags/spark_etl_dag.py):
Crie um arquivo Python e adicione o código abaixo:
Passo 2 – Valide no Airflow UI
Acessa a UI do Airflow acessando a URL http://localhost:8080
Para mais informações sobre como iniciar o Airflow, acesse o capítulo 4
Busque pela DAG spark_etl_pipeline

Clique no botão Trigger (▶) no canto superior direito do console.

Confira os logs no Airflow e verifique se os arquivos Parquet foram criados em /tmp/produtos_metricas_airflow.
Após a execução, acesse a aba Logs e veja o Output
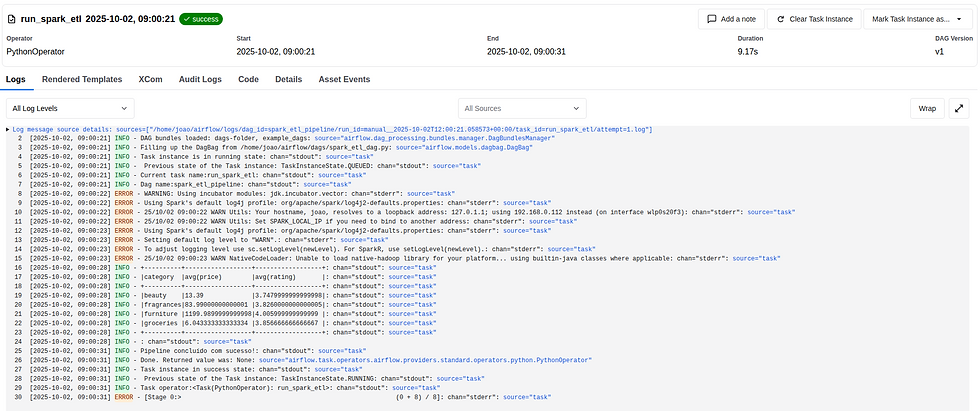
Pronto! Você acaba de criar um ETL usando Spark integrada ao Airflow! Bora pra próxima?
Leituras recomendadas
Conclusão
Agora você tem um pipeline Spark automatizado e monitorado pelo Airflow. Com isso, você aprendeu:
a importância da orquestração,
como rodar Spark de forma agendada,
e como monitorar resultados diretamente no Airflow.
O que vem a seguir?
👉 Nos próximos capítulos, vamos falar de persistência e formatos de dados (Cap. 7), explorando como salvar e ler dados em CSV, JSON e Parquet.
Gostou desse capítulo?
👉 Assine a newsletter Coffee & Tips e receba os próximos capítulos direto no seu e-mail.
👉 Pré-venda exclusiva
Em breve também vamos lançar um E-Book avançado, com tutoriais em Spark, Airflow, Redshift, tudo para você se tornar um Engenheiro de Dados!
Cadastre-se agora na lista de pré-venda e garanta:
Acesso antecipado antes do lançamento oficial 🚀
Benefícios exclusivos para inscritos 💡
Conteúdo extra que não estará disponível gratuitamente
Fique ligado!


Comentários