Primeiros passos com DBT - Data Build Tool
- JP

- 15 de dez. de 2022
- 7 min de leitura
Atualizado: 29 de abr. de 2023
O DBT tem sido utilizado por muitas empresas na área de Dados e acredito que podemos extrair bons insights neste post sobre ele. Esse vai ser um post prático mostrando como o DBT funciona e espero que vocês gostem.

O que é DBT?
DBT significa Data Build Tool e permite que equipes transformem os dados já carregados em seu warehouse através de operações de DML como um simples Select. DBT representa o T no processo de ELT, ou seja, ele não trabalha para extrair e carregar dados mas sim, para transformá-los.
Passo 1: Criando o projeto DBT
Agora, assumimos que o DBT já esteja instalado, mas se não estiver, recomendo consultar este link para mais informações.
Após a instalado, você pode criar um novo projeto usando CLI ou pode clonar este projeto do repositório DBT no Github.
Aqui para este post, vamos usar o modo CLI para criar nosso projeto e também para concluir as próximas etapas. Para criar um novo projeto, execute o comando abaixo no seu terminal.
dbt initDepois de executar o comando acima, você precisa digitar o nome do projeto e qual warehouse ou banco de dados você vai usar conforme a imagem abaixo.
Para este post, vamos usar o adaptador do postgres. É muito importante que você tenha o banco de dados postgres já instalado ou você pode criar uma imagem postgres usando o docker.
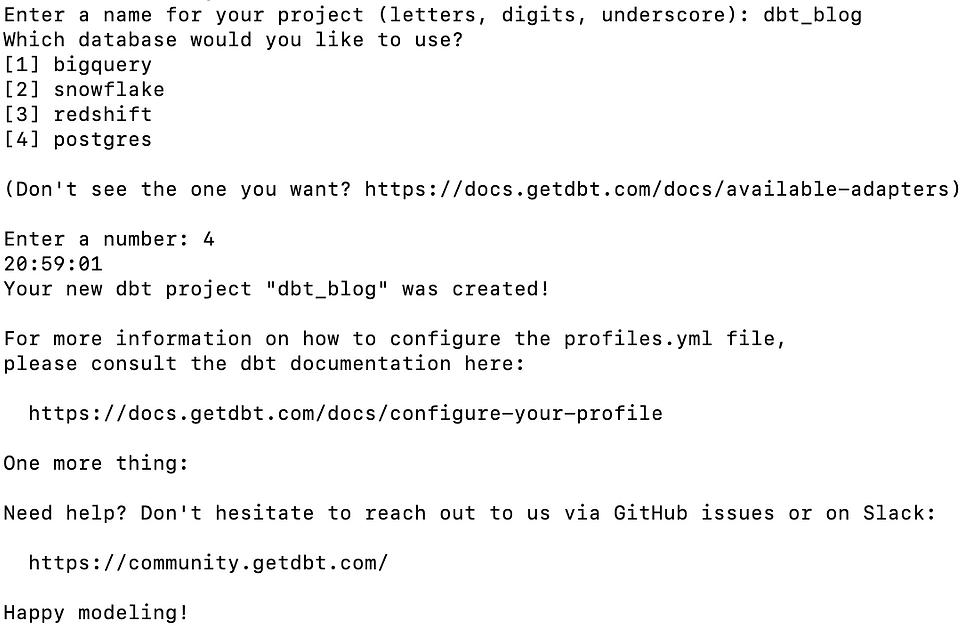
Sobre os adaptadores, o DBT suporta vários deles e você pode conferir aqui.
Criei uma estrutura de tabela e também carreguei os dados simulando dados de uma plataforma de vídeo chamada wetube e vamos utilizá-los para entender como o DBT funciona. Acompanhe a estrutura:

Passo 2: Estrutura e mais sobre DBT
Após executar o comando dbt init para criar o projeto, uma estrutura de pastas e arquivos abaixo será criada.
Não vou falar sobre todos os diretórios do projeto, mas gostaria de focar em dois deles.

Sources
Antes de falarmos sobre os dois diretórios, vamos falar sobre os Sources, são basicamente os dados já carregados em seu warehouse. No processo DBT, as fontes têm o mesmo significado de dados brutos.
Não há pastas que representem dados Sources para este projeto, mas você precisa saber sobre este termo pois vamos configurar tabelas já criadas como Sources para as próximas seções.
Seeds
Seeds é um diretório que oferece um mecanismo interessante e útil para carregar dados estáticos em seu warehouse por meio de arquivos CSV. Se você deseja carregar esses dados, você precisa criar um arquivo CSV neste diretório e executar o comando abaixo.
dbt seedPara cada campo no arquivo CSV, o DBT irá inferir os tipos e criará tabelas e suas colunas no warehouse ou banco de dados.
Models
O DBT funciona com o paradigma de Model, a ideia principal é que você pode criar modelos através da transformações utilizando instruções SQL baseadas em fontes de tabelas ou modelos existentes
Cada arquivo SQL localizado na pasta de model criará um modelo em seu warehouse ou banco de dados quando o comando abaixo for executado.
dbt runLembre-se que um modelo pode ser criado através de uma fonte ou outro modelo e não se preocupe com isso, vou mostrar mais detalhes sobre isso.
Passo 3: Configurando a configuração com o banco de dados
Com o projeto já criado, precisamos configurar a conexão com o banco de dados e aqui neste post vamos usar o postgres como banco de dados.
Depois de inicializar o projeto, vários arquivos são criados e um deles é chamado de profiles.yml.
profiles.yml é o arquivo é responsável por controlar os diferentes perfis/profiles para as diferentes conexões com os bancos de dados, como ambiente de desenvolvimento e produção. Se você notou, não podemos ver este arquivo na imagem acima porque este arquivo é criado fora do projeto para evitar credenciais que sejam confidenciais. Você pode encontrar esse arquivo no diretório ~/.dbt/.

Se você observar, temos um perfil chamado dbt_blog e um destino chamado dev, por padrão, o destino refere-se a dev com as configurações de conexão do banco de dados. Além disso, é possível criar um ou mais perfis e alvos(target), permitindo trabalhar com diferentes ambientes.
Outro detalhe importante é que o perfil dbt_blog deve ser especificado no arquivo dbt_project.yml como um perfil padrão. Nas próximas seções, discutiremos o que é e como o arquivo dbt_project.yml funciona.
Passo 4: Criando o arquivo dbt_project.yml
Todo projeto DBT possui um arquivo dbt_project.yml, você pode configurar informações como nome do projeto, diretórios, perfis e tipo de materialização.
name: 'dbt_blog'
version: '1.0.0'
config-version: 2
profile: 'dbt_blog'
model-paths: ["models"]
analysis-paths: ["analyses"]
test-paths: ["tests"]
seed-paths: ["seeds"]
macro-paths: ["macros"]
snapshot-paths: ["snapshots"]
target-path: "target" # directory which will store compiled SQL files
clean-targets: # directories to be removed by `dbt clean`
- "target"
- "dbt_packages"
models:
dbt_blog:
# Config indicated by + and applies to all files under models/example/
mart:
+materialized: tableObserve que o campo de profile foi configurado como o mesmo profile especificado no arquivo profiles.yml e outro detalhe importante é sobre o campo materialized. Aqui foi configurado como um valor table, mas por padrão, é uma view.
O campo materialized permite que você crie modelos como uma tabela ou view em cada execução. Existem outros tipos de materialização, mas não vamos discutir aqui e eu recomendo ver a documentação do dbt.
Passo 5: Criando nosso primeiro modelo
Criando os primeiros arquivos
Vamos mudar um pouco e vamos criar uma subpasta no diretório do model chamada mart e dentro desta pasta vamos criar nossos arquivos .SQL e também outro arquivo importante que ainda não discutimos chamado schema.yml.
Criando o arquivo schema
Os arquivos de schema são usados para mapear fontes e documentar modelos como o nome do modelo, colunas e muito mais. Agora você pode criar um arquivo chamado schema.yml e preencher com as informações abaixo.
version: 2
sources:
- name: wetube
tables:
- name: account
- name: city
- name: state
- name: channel
- name: channel_subs
- name: video
- name: video_like
- name: user_address
models:
- name: number_of_subs_by_channel
description: "Number of subscribers by channel"
columns:
- name: id_channel
description: "Channel's ID"
tests:
- not_null
- name: channel
description: "Channel's Name"
tests:
- not_null
- name: num_of_subs
description: "Number of Subs"
tests:
- not_nullSources: No campo source você pode incluir tabelas do seu warehouse ou banco de dados que serão utilizadas na criação do modelo.
models: No campo models você pode incluir o nome do modelo, colunas e suas descrições
Criando um modelo
Esta parte é onde podemos criar scripts .SQL que resultarão em nosso primeiro modelo.
Para o primeiro modelo, vamos criar uma instrução SQL para representar um modelo que podemos ver os números de inscritos do canal. Vamos criar um arquivo chamado number_of_subs_by_channel.sql e preenchê-lo com os scripts abaixo.
with source_channel as (
select * from
{{ source('wetube', 'channel') }}
),
source_channel_subs as (
select * from
{{ source('wetube','channel_subs') }}
),
number_of_subs_by_channel as (
select
source_channel.id_channel,
source_channel.name,
count(source_channel_subs.id_subscriber) num_subs
from source_channel_subs
inner join source_channel using (id_channel)
group by 1, 2
)
select * from number_of_subs_by_channelEntendendo o modelo
Observe que temos vários scripts separados por expressão de tabela comum (CTE) que se torna útil para entender o código.
O DBT permite usar o template Jinja {{ }} trazendo uma maior flexibilidade ao nosso código.
O uso da palavra-chave source dentro do modelo Jinja significa que estamos nos referindo a tabelas de origem. Para referenciar um modelo, você precisa usar a palavra-chave ref.
A última instrução SELECT baseada nas tabelas de origem (source) irá gerar o modelo (model) como tabela no banco de dados.
Executando o nosso primeiro modelo
Execute o comando abaixo para criar nosso primeiro modelo baseado nos arquivos anteriores.
dbt runSaída

Criando um novo modelo
Imagine que precisamos criar um novo modelo contendo as informações da conta e seus canais. Vamos voltar ao arquivo schema.yml para adicionar esse novo modelo.
- name: account_information
description: "Model containing account information and it's channels"
columns:
- name: id_account
description: "Account ID"
tests:
- not_null
- name: first_name
description: "First name of user's account"
tests:
- not_null
- name: last_name
description: "Last name of user's account"
tests:
- not_null
- name: email
description: "Account's email"
tests:
- not_null
- name: city_name
description: "city's name"
tests:
- not_null
- name: state_name
description: "state's name"
tests:
- not_null
- name: id_channel
description: "channel's Id"
tests:
- not_null
- name: channel_name
description: "channel's name"
tests:
- not_null
- name: channel_creation
description: "Date of creation name"
tests:
- not_nullAgora, vamos criar um novo arquivo SQL e nomeá-lo como account_information.sql e adicionar os scripts abaixo:
with source_channel as (
select * from
{{ source('wetube', 'channel') }}
),
source_city as (
select * from
{{ source('wetube','city') }}
),
source_state as (
select * from
{{ source('wetube','state') }}
),
source_user_address as (
select * from
{{ source('wetube','user_address') }}
),
source_account as (
select * from
{{ source('wetube','account') }}
),
account_info as (
select
account.id_user as id_account,
account.first_name,
account.last_name,
account.email,
city.name as city_name,
state.name as state_name,
channel.id_channel,
channel.name as channel,
channel.creation_date as channel_creation
FROM source_account account
inner join source_channel channel on (channel.id_account = account.id_user)
inner join source_user_address user_address using (id_user)
inner join source_state state using (id_state)
inner join source_city city using (id_city)
)
select * from account_infoCriando nosso último modelo
Para o nosso último modelo, vamos criar um modelo sobre quantas curtidas tem um vídeo. Vamos alterar novamente o schema.yml para descrever e documentar nosso futuro e último modelo.
- name: total_likes_by_video
description: "Model containing total of likes by video"
columns:
- name: id_channel
description: "Channel's Id"
tests:
- not_null
- name: channel
description: "Channel's name"
tests:
- not_null
- name: id_video
description: "Video's Id"
tests:
- not_null
- name: title
description: "Video's Title"
tests:
- not_null
- name: total_likes
description: "Total of likes"
tests:
- not_nullCrie um arquivo chamado total_likes_by_video.sql e coloque o código abaixo:
with source_video as (
select * from
{{ source('wetube','video') }}
),
source_video_like as (
select * from
{{ source('wetube','video_like') }}
),
source_account_info as (
select * from
{{ ref('account_information') }}
),
source_total_like_by_video as (
select source_account_info.id_channel, source_account_info.channel,
source_video.id_video, source_video.title, count(*) as total_likes
FROM source_video_like
inner join source_video using (id_video)
inner join source_account_info using (id_channel)
GROUP BY source_account_info.id_channel,
source_account_info.channel,
source_video.id_video,
source_video.title
ORDER BY total_likes DESC
)
select * from source_total_like_by_videoExecutando novamente
Após a criação dos arquivos, vamos executar DBT novamente para criar os novos modelos
dbt runSaída

Os modelos foram criados no banco de dados e você pode executar instruções select diretamente em seu banco de dados para verificá-lo. Perceba que além dos modelos criados, você pode notar as demais tabelas que foram mapeadas no arquivo schema.yml e que já existiam na estrutura do banco inicial. Lembre-se do mecanismo de criar tabelas estáticas através do diretório Seeds, pode ser uma boa escolha para uma carga inicial.

Modelo: account_information

Modelo: number_of_subs_by_channel

Modelo: total_likes_by_video

Passo 6: DBT Docs
Documentação
Depois de gerados nossos modelos, agora vamos gerar documentos com base nestes. O DBT gera uma documentação completa sobre modelos (models), sources e suas colunas, através de uma página da web.
Gerando as docs
dbt docs generateDisponibilizando as docs no servidor Web
Após a geração dos documentos, você pode executar o comando abaixo no seu terminal para iniciar um servidor da Web na porta 8080 e consultar a documentação localmente utilizando o seu navegador. Caso o navegador não abra automaticamente, digite o seguinte endereço localhost:8080 no seu navegador.
dbt docs serve



Lineage
Outro detalhe sobre a documentação é que você pode ver através de um Lineage os modelos e suas dependências.



Código no Github
Você pode conferir esse código na nossa página do Github.
Curtiu? Eu espero que tenha gostado!



Comentários